
Optical generative models: Bringing diffusion AI into the physics of light


Generative models have transformed artificial intelligence. From realistic image synthesis and natural language processing to molecular design, their reach spans nearly every domain of science. Yet this success comes at a cost: the models are growing ever larger, requiring immense computational resources, longer inference times, and increasingly unsustainable energy consumption. Diffusion models, in particular, dominate state-of-the-art image and video generation, but their billions of parameters and iterative denoising steps strain even the most advanced GPUs.
This raises a pressing question: can we imagine a different physical substrate for generative AI—one that is both scalable and energy efficient? Optics and photonics have long been explored for accelerating computations, given the inherent parallelism and near-zero latency of light propagation. What if generative AI itself could be implemented in light?
In a landmark paper Shiqi Chen, Yuhang Li, Yuntian Wang, Hanlong Chen, and Aydogan Ozcan present precisely this vision: optical generative models that implement diffusion-inspired image synthesis not digitally, but through free-space optical propagation.
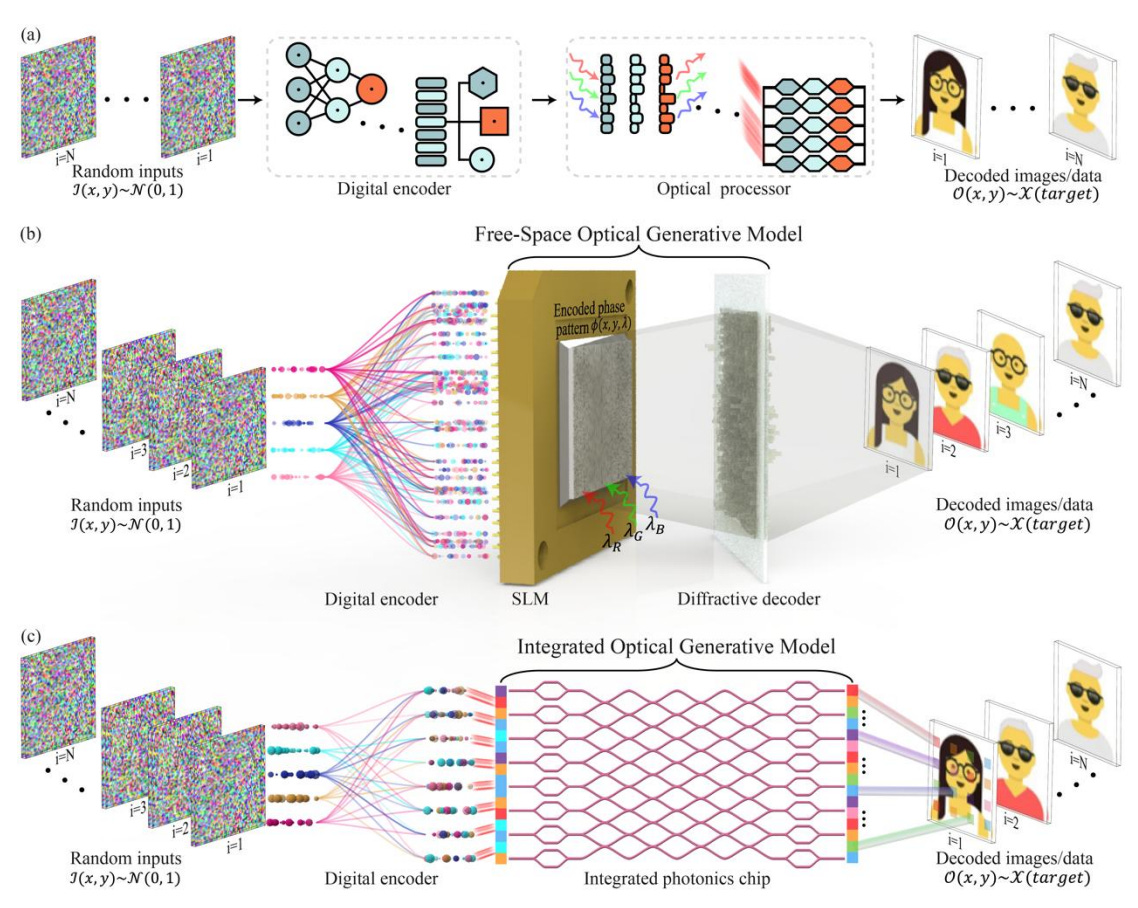
The architecture: seeds, decoders, and light
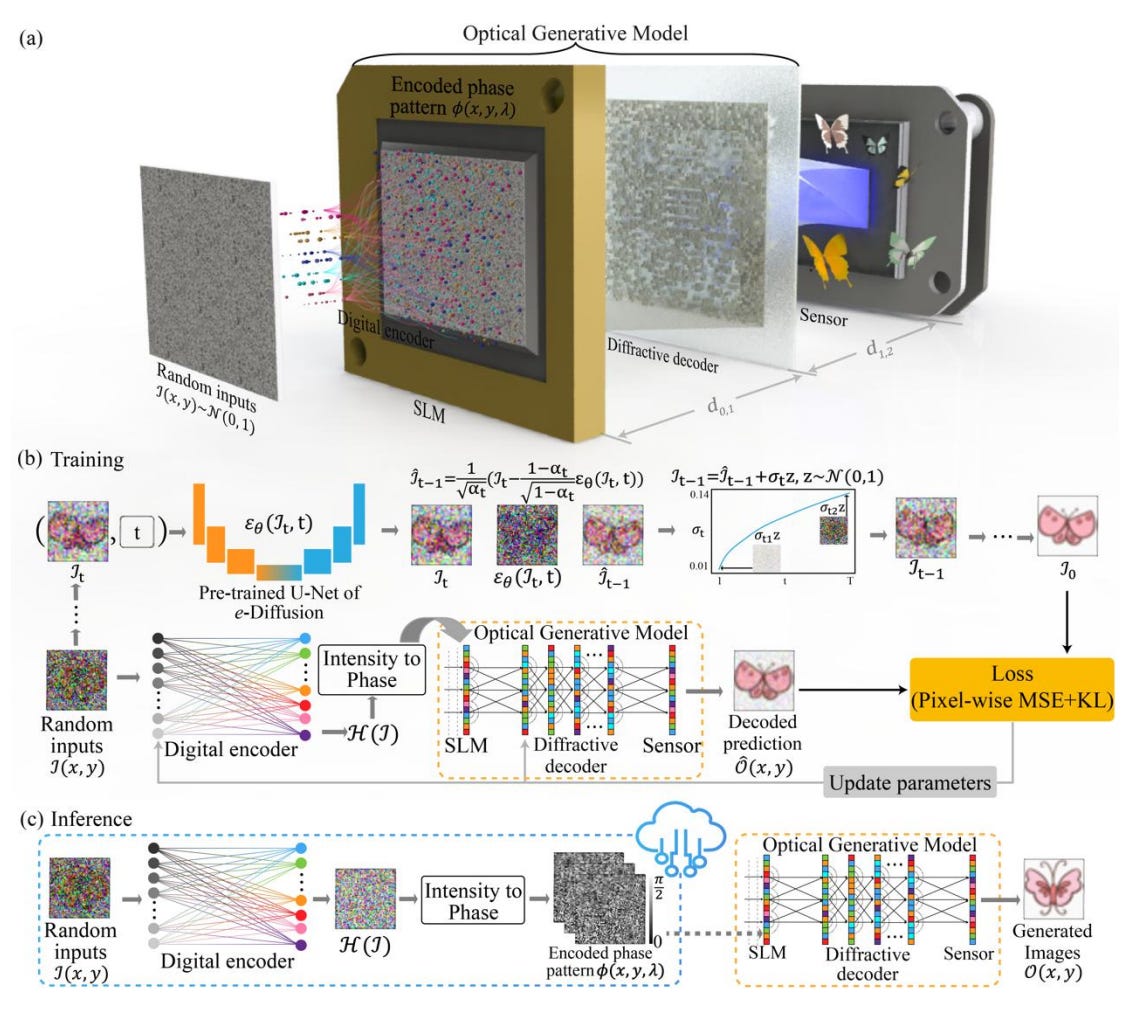
The key idea is deceptively elegant. A shallow digital encoder takes random noise and transforms it into phase patterns—“optical generative seeds.” These seeds are displayed on a spatial light modulator (SLM) and illuminated by coherent light. The light propagates through a diffractive decoder, a reconfigurable optical structure jointly trained with the encoder, which directly synthesizes new images following a target data distribution.
Except for the small energy cost of generating seeds and providing illumination, no conventional computation is used during inference. The generative step—the creation of a new image from noise—is carried out entirely by the physics of light propagation. The latency is on the order of nanoseconds, limited only by the refresh rate of the SLM.
The authors demonstrate both snapshot optical generative models, which generate an image in a single forward pass of light, and iterative optical generative models, which mimic the multi-step denoising process of digital diffusion models by sequential optical iterations. In both cases, the system captures the structure of complex data distributions, producing not just copies of training examples but genuinely new images consistent with the learned distribution.
To test the concept, the team generated handwritten digits (MNIST), fashion products (Fashion-MNIST), butterflies, human faces (CelebA), and even Van Gogh-style artworks—both in monochrome and multicolor. Image quality was assessed using standard machine learning benchmarks such as the Inception Score (IS) and the Fréchet Inception Distance (FID), showing performance statistically comparable to digital neural networks.
Implications and outlook
The implications of this work are far-reaching. By offloading the computationally expensive part of generative modeling to optics, the energy footprint of inference can be drastically reduced. The authors estimate that for some tasks, optical generation can consume orders of magnitude less energy than GPU-based diffusion models, especially when images are intended for direct visualization (such as displays, augmented reality, or head-mounted devices) where the data does not need to be converted back into digital form.
Moreover, the architecture is flexible. By retraining the encoder and reconfiguring the diffractive decoder, the same optical platform can switch between data distributions—from digits to faces to artworks—without changes in physical hardware. Iterative optical models further expand the generative capabilities, producing more diverse and higher-quality outputs while avoiding issues like mode collapse.
Challenges remain: alignment tolerances, SLM phase resolution, and fabrication of high-fidelity static decoders are critical technical hurdles. Yet these are solvable with advances in nanofabrication, integrated photonics, and optical materials. Looking forward, one can envision compact optical generative chips capable of creating images, videos, or even multimodal outputs in real time with negligible energy use.
This work by Chen and colleagues not only demonstrates a new paradigm for generative AI but also represents a remarkable example of how physics and machine learning can merge. If diffusion models marked the last great leap in digital generative AI, optical generative models may mark the beginning of an era where intelligence is not just computed—but illuminated.